1USDA-ARS-PGEC, 2University of California-Berkeley, 3University of California-San Diego, 4University of Arizona, 5Maize Genetics Cooperation Stock Center, 6Iowa State University
New ZmDB Blast Alert Service. ZmDB introduces a new Blast Service - Blast Alert! ZmDB users can subscribe their blast search query sequences by filling out a simple registration form. Users will store their query sequences and blast specifications at ZmDB. An initial blast search will be carried out against the current database and the blast output will be sent to the user by email. For each registered query, a Query-ID is also sent to the user and is required for unsubscribing. If any new blast hits are found whenever ZmDB updates its sequence database, an email alert will be sent to the corresponding user. ZmDB Blast Alert Service can be accessed by clicking the "Search ZmDB" button at the ZmDB front page.
Table 1. Key Components of the Project
| Subproject | Status | Comments |
| Sequence 50,000 ESTs | Currently ~95,000; ~28,000 Tentative Unique Genes | Exciting discovery that organs express different members of gene families; >2200 complete cDNAs |
| ZmDB web site | zmdb.iastate.edu key resource for corn | Databases maintained 1. EST assembly 2. Phenotypes of mutants 3. Microarray protocols & data 4. Genomic sequences. |
| RescueMu site sequencing | ~4,000 likely germinal mutations sequenced with goal of 15,000 | 1 MB per month of gene-enriched maize genomic DNA per month. More than half of the sequences flanking likely germinal insertions of RescueMu are readily identified as genes by matches to ESTs. Only 4% of insertions match retrotransposons. |
| Phenotypes of Mu-induced mutants | On-going in the Sachs, Freeling, Schmidt, Smith and Hake labs | Ear, kernel and seedling screening for >20,000 families. Summer 2001 in-depth 3000 adult families screened at the Coop. We plan to repeat the adult screen next year. |
| Microarraying ESTs | 4 array types now, with Unigene set in 2001-2002 | Major effort managed by Univ. AZ (David Galbraith, Vicki Chandler). Current arrays cover 11,000 "genes" and the Unigene1.1, 1.2 and 1.3 arrays will cover ~24,000 |
| Postdoctoral training | 4 fellows | 1 fellow at Stanford (oligo arrays); 1 at Arizona (microarray); 2 fellows at ISU (bioinformatics & intron retention experiments) |
| Library plates: Immortalized RescueMu | Resource for PCR screening to find germinal insertions | Initial plates available from summer 2000 tagging populations with transposed RescueMu elements |
EST Sequencing. We have deposited nearly twice the original goal of 50,000 high quality ESTs (majority are phred >40, far above the GenBank minimum of 15 = 1 error per 33 bases for ESTs) mainly from inbreds B73, W23, and Oh43. Average length varies per library and has ranged from 380 bp to 520 bp. EST sequencing will continue during 2001-2002 (fourth project year) toward a new goal of 120,000 ESTs. We have been remarkably fruitful in gene discovery with >28,000 likely genes so far from the complete maize database of >114,000 ESTs. If short (100-200 b) and low quality, mainly pre-1998 ESTs are eliminated, ~25,000 genes are defined by ESTs. We attribute our success to libraries prepared from specific developmental stages of different organs. Our current project is BMS tissue culture cells; this library will be deeply sampled as the initial 1000 clones indicate very high diversity.
Our major findings from EST analysis are [1] that maize alleles are quite polymorphic and [2] that specific gene family members are expressed in different organs. In contrast, when such ESTs share >80-85% similarity over ~100 bases, they show a similar pattern of hybridization on microarrays fabricated with the Maize Gene Discovery ESTs (Fernandes et al., 2002; Y. Cho et al., in preparation). Comparisons of ESTs always have the criticism that insufficient sampling prevents detection of rare transcripts, but for gene families with robust EST support, we often find quite different patterns of expression. For example, TUC (Tentative Unique Contig) 09-07-6344.1 and TUC09-07-7818.1 share >99% sequence similarity to maize cytosolic glyceraldehyde-3-phosphate dehydrogenase genes Gpc3 and Gpc4, respectively. Eleven ESTs derived from the mixed late tassel stages library were from Gpc4 (TUCO9-07-7818.1), but none were found for Gpc3 (TUCO9-07-6344.1). TUC04-05-8646.1 and TUC07-14-6306 both share ~95% nucleotide sequence and high overall similarity to maize 22kDa alpha zein protein. TUC04-05-8646.1 is expressed in seedling root tissue (library 614) as judged by the presence of 20 ESTs, although there are no matches to TUC07-14-6306. In contrast TUC07-14-6306 has ESTs expressed in the early embryo library (687), but there are no TUC04-05-8646.1 ESTs in the embryo group. It seems very unlikely that there has been contamination with endosperm in either the root or embryo libraries because none of the common zeins dominating endosperm expression were found. A third example of possible tissue-specific expression is provided by TUC01-26-861.2 and TUC07-14-6194.1, which share ~89% sequence similarity to a subunit of the vacuolar proton ATPase. TUC07-14-6194.1 is expressed in root with 23 ESTs from library 614, but no ESTs were recovered from any other source. There are no root ESTs in the likely homeologous TUC01-26-861.2. These data convince us that examination of gene-specific expression patterns using tools with greater resolution than cDNA microarrays will be required to properly annotate the transcript distribution of individual genes.
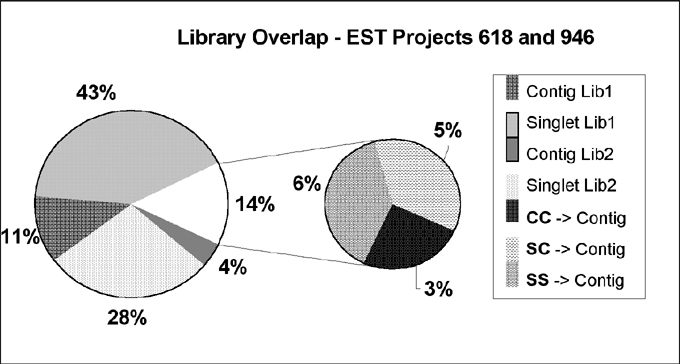
Figure 1. ESTs from 2 cm (618) and 1-2 mm (946) immature tassels overlap by only 14%. More than 5000 ESTs from two stages of tassel development were compared for overlaps of 50 bases, >95% similarity. C = contig; S = singlet.
Maize Gene Discovery Microarrays. Approximately 15 months after starting EST sequencing, coPI Galbraith began distributing microarrays: two identical slides for $150. >600 slides have been distributed as of Nov. 2001. PCR yield of cDNA inserts has been ~90% up to 96%, ensuring excellent coverage of the EST diversity. By using leftover plasmid sequencing templates or the consolidated clones from Stanford, we effectively eliminate "tracking problems" in going from sequencing to microarrays. Thus far four EST projects, ~11,000 genes, are available http://gremlin3.zool.iastate.edu/zmdb/microarray/progress.html. The first of three Unigene1 slide types with 8,000 genes each will be available soon. The 24,000 Unigene1 array set should be available by December 2002. We estimate that Unigene arrays will contain about half of the expected number of maize genes.
Sequencing Genomic DNA. The second route to gene discovery is sequencing genomic DNA in a strategy that combines gene discovery with a key step in functional genomics, generating an insertional mutant. RescueMu, a 4.7 kb Mu1 derivative with pBluescript and other markers, inserts preferentially into genes and allows direct cloning of flanking maize DNA into E. coli (Raizada et al. 2001). Mutagenized plants are grown in grids of up to 48 rows and 48 columns, DNA is prepared from tissue samples from an entire row or column, and 96 (48 rows + 48 columns) E. coli libraries immortalize the RescueMu insertion sites. Maize inserts of up to 15 kb are amplified by PCR protocol; given the relatively compact size of maize introns (85% are <200 bp) most RescueMu plasmids contain an entire gene and its regulatory regions within the average ~ 6 - 7 kb maize insert. 96-well library plates containing the recovered plasmids organized by rows and columns of the grids are available to the community for PCR screening to find insertions in genes of interest. Heritable (or very rare, early somatic insertions) will be represented in both a row and a column; seed for germinal mutants is obtained from the Maize Coop. To complement ESTs for gene discovery, the Project is sequencing row plasmids (bidirectionally, about 400 bases from each Mu end), with a goal of completing 8 grids, about 15,000 likely germinal insertions and 30 MB of genomic sequences enriched for genes. This genomic sequence will identify genes not yet found by EST sequencing. The genomic DNA also contains presumptive introns and promoter regions, recognized after annotation against ESTs by the ISU staff; all of these results are displayed through ZmDB http://zmdb.iastate.edu.
In the Protocols section you will find information for efficiency screening of library plates to determine which plant has a likely germinal insertion mutation of interest to you. Also, the sequencing plan does not identify all germinal insertions (by definition these are sequenced multiple times), hence you may find it useful to do a PCR screen to determine if there is both a row and a column insertion in your favorite gene. Also, the library plates each contain a collection of 10 � 50% of the "gene-rich" part of the corn genome. A somatic plasmid of your favorite gene could contain the regulatory region and other information that interests you. Such plasmids can be found by transforming the DNA samples into E. coli to reconstruct a "gene-enriched" library.
Overcoming Transposon Biology to Make Mutants More Efficiently. We encountered a serious problem in scaling from the few dozen plants analyzed initially to the thousands in early grids. RescueMu transposition out of the transgene arrays was only 10-30%, compared to the ~100% of Mu1. In a massive project coordinated by coPI Vicki Chandler, the team surveyed 1200 RescueMu outcross progeny in January 2000 by DNA blot hybridization to identify individuals with transposed RescueMu but no transgene array. Fourteen individuals had 2 or 3 transposed RescueMu, and these were outcrossed multiple times to generate the tagging populations for summer 2000. In the Stanford 2000 grid, we found 100% RescueMu insertion frequency from the once transposed elements; other grids had 150% tagging efficiency. Now we are testing two smaller RescueMu elements, miniMu (2.2 kb) and midiMu (2.7 kb) in a new "cleaner" Mutator background (multiple transposase-encoding MuDR but few other Mu elements) and in a standard, medium copy Mu line. Native 1.4 - 2.2 kb Mu elements transpose more frequently than larger elements, and the smaller plasmid size will be more amenable to shotgun sequencing approaches.
Phenotype Database and Direct Access to Transposon-Tagged Mutants. Each plant in a RescueMu grid is self-pollinated (or outcrossed if male or female sterile). Because we have systematically selected for the absence of Mutator silencing and new germinal insertions of RescueMu, the forward mutation frequency of our materials is about twice the "best lines" reported by Don Robertson. Eight percent of ears have segregating seed mutations, at the seedling stage15 - 28% of families have a visible mutation, and adult families have nearly a 40% mutation frequency (1154 mutants in 3000 families). CoPI Marty Sachs and his staff at the Maize Coop manage the seed and ear screen, and propagate lines as needed. coPI Mike Freeling performs a detailed seedling phenotype screen at UC-Berkeley. Descriptions in a controlled vocabulary and photos are logged into a ZmDB database designed by UC-SD and ISU. During the summer of 2001 we hosted an adult plant phenotype screen at the Maize Coop. 14 Maize Gene Discovery personnel (including four summer REU students) and community researchers annotated 3000 families of 30 individuals each. All phenotypes found in two or more individuals were logged and checked by two scorers. Most new mutants are caused by standard Mu elements. Nonetheless, RescueMu sequencing identifies likely germinal insertions into many genes, and seed requests based on insertion location have started. Furthermore, our public phenotype database can greatly accelerate maize research. It is difficult and time-consuming to establish effective Mutator populations and to analyze the phenotypes; now, maize researchers can go on line to screen phenotypes: http://zmfmdb.zool.iastate.edu/layout/default.htm and get seed from the Coop. There are "no strings" attached to seed distribution.
Database of Project Information and Analytical Tools. ZmDB is
the gateway to Maize Gene Discovery project data, materials, and analytical
tools. CoPI Brendel manages ZmDB, and he and his laboratory have written
software for gene identification and splice site prediction. As we relate
EST data with genomic sequences obtained from the RescueMu-tagged
sites, we face the same annotation problems as encountered in whole genome
sequencing efforts. We have devised a number of computational tools that
greatly facilitate our work. The SplicePredictor program assigns
probabilities to potential splice sites based on species-specific training.
(Brendel & Kleffe, 1998; Xing & Brendel, 2000). The GeneSeqer
program implements a dynamic programming algorithm for spliced alignment
of ESTs or proteins to genomic DNA, with scores optimizing both sequence
similarity and splice site probabilites (Usuka et al., 2000; Usuka &
Brendel, 2000). An upcoming service will be a registered sequence search
conducted by ZmDB staff; individuals can post sequences for 3 months and
receive notification when a new EST or RescueMu genomic sequence
is a match.
Return to the MNL 76 On-Line Index
Return to the Maize Newsletter Index
Return to the MaizeGDB Homepage
{kind=link}