University of Freiburg
Characterization of cDNAs encoding the maize TFIID proteins
--Michael M. Haass and Günter Feix
The TFIID protein is a general transcription factor binding to the TATA sequence element located upstream of the transcription start site of most polymerase II transcribed genes. Together with further factors of this class, such as TFIIA, B, E and F, it represents an essential part of the active transcription initiation complex at the core promoter region and may serve as a continuous switch for gene regulation by activators (Meisterernst et al., Cell 66:981-993, 1991; Meisterernst and Roeder, Cell 67:557-567, 1991).
Extensive studies of the structure and function of TFIID proteins have been performed with the respective yeast and human TFIID proteins. In plants, the first TFIID gene structures from Arabidopsis were recently described (Gasch et al., Nature 346:390-394, 1990) indicating, in contrast to the monogenic situation in yeast or animals, the occurrence of two genes.
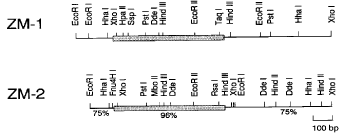
We now report that the TFIID proteins are encoded by at least two genes in maize also. The sequence analysis of cDNA clones isolated from a maize leaf cDNA library (using the sequence of a conserved C-terminal part of the Arabidopsis TFIID AT-1 cDNA as a hybridisation probe) revealed so far the presence of two different active genes (shown in the figure).
Restriction enzyme maps and schematic alignment of the cDNA clones ZM-1 and ZM-2. The boxed regions represent the ORFs. The percentage numbers indicate the homology between the cDNAs.
The maize cDNAs ZM-1 and ZM-2 display a higher overall DNA sequence homology to each other than do the Arabidopsis cDNAs AT-1 and AT-2. In comparison with the Arabidopsis TFIID clones they show about 70% homology at the DNA, and about 90% homology at the protein level.
The sequence of the N-terminal 18 amino acids of both maize TFIID proteins
(as deduced from the cDNA sequences) differs from the amino acid sequence
of the other known TFIID proteins, while the remaining 180 amino acids
show a strong structural conservation displaying two direct repeat regions
(probably involved in DNA binding), a central domain rich in basic residues
(thought to be involved in protein-protein interactions) and a region similar
to prokaryotic sigma factors (Hoffmann et al., Nature 346:387-390, 1990).
Return
to the MNL 66 On-Line Index
Return to
the Maize Newsletter Index
Return to the MaizeGDB Homepage
{kind=link}