Michigan Technological University
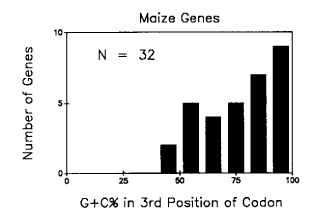
Figure 1. A plot of the number of maize genes versus the G+C percent in the third position of the codons of their respective coding sequences. A 5% G+C window was used. The data were taken from Gowri & Campbell, Plant Physiol. in press, 1989.
This difference in codon usage among maize nuclear genes is clearly illustrated when homologous genes are compared. For example, chloroplastic and cytosolic glyceraldehyde-3-phosphate dehydrogenase (MZEG3PD1 & MZEG3PD2) differ significantly in codon usage with MZEG3PD1 using a total of 39 codons for all amino acids encoded and a preferred set of 29 codons and MZEG3PD2 using a total of 51 codons and a preferred set of 40 codons. A similar difference in codon usage among the catalase genes is also found with MZECAT1 and MZECAT2 having a codon preference like MZEG3PD2, while MZECAT3 resembles MZEG3PD1 in codon usage pattern. The data available on nuclear genes of other monocots show a similar difference, but fewer examples are available to illustrate it using homologous genes. However, these differences in homologous genes are not found when the dicots are analyzed. Thus, it would appear that different mechanisms governing silent mutations in coding sequences of monocots and dicots have been operating during the evolution of these species.
We also noted in our review on codon usage in plant genes that the bimodal pattern of percentage of G+C in the 3rd position of codons for monocot nuclear genes was similar to the pattern observed for human genes (and perhaps other warm-blooded vertebrates). The bimodal distribution of codon usage in human genes has been explained by the finding that the human genome is a mosaic of A+T and G+C rich regions, which have been called isochores (Aota & Ikemura, Nucl. Acid Res. 14:6345, 1986). Wolf et al.(Nature 337:283, 1989) showed that A+T and G+C rich regions of mammalian genomes have different rates of mutation at silent sites, which may account in part for the existence of isochores in the genomes of these organisms. This leads to the question: do isochores exist in the nuclear genome of maize and does this account for the differences in codon usage among maize nuclear genes?
Bernardi and coworkers (Salinas et al.,
Nucl. Acids Res. 16:4269, 1988; Matassi et al., Nucl. Acids Res. 17:5273,
1989) have analyzed plant nuclear genomes to determine if isochores exist.
Originally, they used buoyant density analysis of genomic DNA fragments
to compare 3 dicots and 3 monocots, but more recently, they compared 5
dicots and 9 monocots. They concluded that isochores exist in all plant
genomes, but that the usual distribution is toward a lower G+C content
in the genomes of dicots as compared to monocots. However, the recent study
showed a dicot (Oenothera hookeri) with a much higher and a monocot
(Allium cepa) with a much lower G+C content. But their analysis
of Poaceae indicates that all grasses have a high G+C content, including
maize, and these species display evidence for isochores in their nuclear
genomes. They suggest that the bimodal distribution of codon usage among
monocot genes which have been sequenced is found because these genes come
from different regions of their respective genomes with differences in
G+C content. Thus, in the future as more maize genes are sequenced and
mapped to their chromosomes, it should be possible to relate their G+C
content and predict the isochore structure of the maize genome. However,
the mechanism underlying the evolution of the maize genome into a mosaic
structure of A+T and G+C rich regions is yet to be explained. Furthermore,
it is not clear why some plant genomes have evolved toward a higher G+C
content relative to others. Finally, it would appear that the differences
in codon bias among maize nuclear genes, which probably reflects their
genomic environment more than other features such as mRNA stability or
translation efficiency, may have little physiological significance.
Return to the MNL 64 On-Line Index
Return to the Maize Newsletter Index
Return to the MaizeGDB Homepage
{kind=link}