--David M. Bashe and Joseph P. Mascarenhas
The genes of various eukaryotic organisms exhibit marked differences in their patterns of choice for synonymous codons. A knowledge of the codon preference for a given organism is useful particularly with regard to determining preferred open reading frames of genes whose identities are unknown, and for back-translating from a known peptide sequence to produce a probe for the gene by which that protein is encoded. The pattern of codon choice is clearest when a large number of known genes are used in the preparation of the codon-usage table. Maruyama et al. (Nucl. Acid. Res. 14S, r151-r197, 1986) have tabulated codon usage tables for all organisms for which more than 5 genes were available using GenBank Genetic Sequence Data Bank Release 38.0, Nov 1985. At that time, only 8 complete coding sequences were available for maize, seven of which were storage proteins. Since cereal storage proteins are very deficient in certain amino acids, some amino acids were underrepresented in their table. A number of additional maize genes have now become available. The present work was undertaken to provide a meaningful table of codon usage. In the process of producing this table, it became apparent that at least one of the zeins (22kD) was not typical of corn in its codon usage profile.
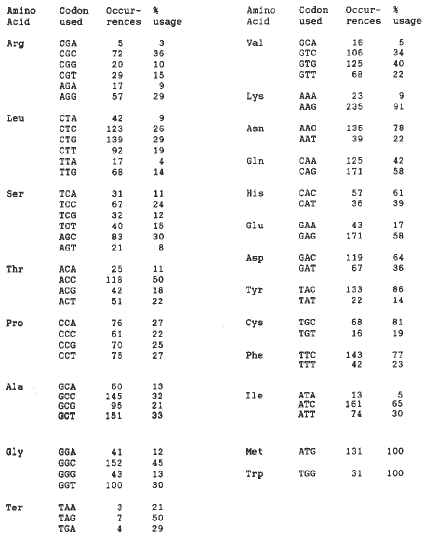
In this study, 25 maize nuclear genes (Table 1) from the GenBank database were selected for analysis. In cases where more than one allele of a gene was available, and the different forms were very similar, only one was used. The results in Table 2 show the number of occurrences of each codon and the number per 100 codons for that amino acid. A strong preference is apparent for codons with a C or a G in the third position.
Table 1. GenBank Sequences used in the preparation of the codon usage table.
Table 2. Table of codon usage derived from GenBank sequences, with the number of occurrences of each codon, and the occurrences per 100 codons for the same amino acid.
Ultimately, the usefulness of a table of codon usage is measured by its ability to distinguish a correct reading frame from an incorrect one. Therefore, this table was used to analyze several maize sequences whose reading frames were known. These results are shown in Table 3. The scoring was calculated as follows: for each codon in the sequence a score was assigned as the percent occurrence of that codon divided by the highest possible percent occurrence of any codon for that amino acid, as determined from the table. The scores for all the codons in the sequence to be scored were summed and divided by the total number of codons to give a percent similarity to the table. The genes in Table 3 were scored in each of the three possible reading frames, over the same region. The first frame is that which has been identified as the coding frame. With the exception of the genes MZEZE22A and MZEZE22B, coding for two 22kD zeins, all the genes tested were correctly distinguished by their codon usage. MZEZE22A and B, however, scored considerably higher in the second reading frame, indicating that their codon usage profile is significantly different from the consensus profile of all the maize genes.
Table 3. Scoring of some maize coding regions on the basis of the codon
usage table.
| Gene tested |
|
||
|
|
|
|
|
| MZEACT1G | 59.3 | 55.4 | 50.2 |
| MZEH4C14 | 81.5 | 54.8 | 47.5 |
| MZEALD | 68.8 | 62.3 | 57.6 |
| MZEH3C2 | 80.0 | 62.5 | 57.9 |
| MZEHSP701,2 | 72.7 | 56.2 | 48.1 |
| MZESUSYSG | 64.9 | 56.4 | 49.0 |
| MZEANT | 61.4 | 55.6 | 52.5 |
| MZEADH1F | 63.3 | 53.1 | 46.6 |
| MZEADH2NR | 73.2 | 59.8 | 46.6 |
| MZETPI1 | 85.3 | 38.4 | 55.7 |
| MZEZE15 | 82.3 | 70.0 | 55.1 |
| MZEZE22A | 59.6 | 70.3 | 50.0 |
| MZEZE22B | 56.9 | 68.7 | 49.3 |
Permission of the authors is not required for citing the codon usage
table.
Return to the MNL 63 On-Line Index
Return to the Maize Newsletter Index
Return to the MaizeGDB Homepage
{kind=link}
{kind=link}